Counting Bytes Faster Than You'd Think Possible
“Summing ASCII Encoded Integers on Haswell at the Speed of memcpy” turned out more popular than I expected, which inspired me to take on another challenge on HighLoad: Counting uint8s. I’m currently only #13 on the leaderboard, ~7% behind #1, but I have already learned some interesting things. In this post I’ll describe my complete solution (skip to that) including a surprising memory read pattern that achieves up to ~30% higher transfer rates on fully memory bound, single core workloads compared to naive sequential access, while apparently not being widely known (skip to that).
As before, the program is tuned to the input spec and the HighLoad system: Intel Xeon E3-1271 v3 @ 3.60GHz, 512MB RAM, Ubuntu 20.04. It only uses AVX2, no AVX512.
The Challenge
“Print the number of bytes whose value equals 127 in a 250MB file full of bytes uniformly sampled from [0, 255] sent to standard input.”
Nothing much to it! The solution presented here is ~550x faster than the following naive program.
uint64_t count = 0;
for (uint8_t v; std::cin >> v;) {
if (v == 127) {
++count;
}
}
std::cout << count << std::endl;
return 0;
The Kernel
You’ll find the full source code of the solution at the end of the post. But first I’ll build up to how it works. The kernel is just three instructions long, so I went straight to an __asm__ block (sorry!).
; rax is the base of the input
; rsi is an offset to current chunk
vmovntdqa (%rax, %rsi, 1), %ymm4
; ymm2 is a vector full of 127
vpcmpeqb %ymm4, %ymm2, %ymm4
; ymm6 is an accumulator, whose bytes
; represent a running count of 127s
; at that position in the input chunk
vpsubb %ymm4, %ymm6, %ymm6
With this, we iterate over 32-byte chunks of the input and:
- Load the chunk with
vmovntdqa(it’s a non-temporal move just for style points, it doesn’t make a difference to runtime). - Compare each byte in the chunk with
127usingvpcmpeqb, giving us back0xFF(aka-1) where the byte is equal to127and0x00elsewhere. For example[125, 126, 127, 128, ...]becomes[0, 0, -1, 0, ...]. - Subtract the result of the comparison from an accumulator. Continuing the example above and assuming a zeroed accumulator, we’d get
[0, 0, 1, 0, ...].
Then, to prevent this narrow accumulator from overflowing, we dump it into a wider one every once in a while with the following:
; ymm1 is a zero vector
; ymm6 is the narrow accumulator
vpsadbw %ymm1,%ymm6,%ymm6
; ymm3 is a wide accumulator
vpaddq %ymm3,%ymm6,%ymm3
vpsadbw sums every eight bytes in the accumulator together into four 64-bit numbers, then vpadddq sums it with a wider accumulator, that we know won’t overflow and that we extract at the end to arrive at the final count.
So far nothing revolutionary. In fact you can find this kind of approach on StackOverflow: How to count character occurrences using SIMD.
The Magic Sauce
The thing with this challenge is, we do so little computation it’s significantly memory bound. I was reading through the typo-ridden Intel Optimization Manual looking for anything memory related when, on page 788, I encountered a description of the 4 hardware prefetchers. Three of them seemed to help purely with sequential access (what I was already doing), but one, the “Streamer”, had an interesting nuance:
“Detects and maintains up to 32 streams of data accesses. For each 4K byte page, you can maintain one forward and one backward stream can be maintained.”
“For each 4K byte page”. Can you see where this is going? Instead of processing the whole input sequentially, we’ll interleave the processing of successive 4K pages. In this particular case interleaving 8 pages seems to be the optimum. We also unroll the kernel a bit and process a whole cache line (2x32 bytes) in each block.
#define BLOCK(offset) \
"vmovntdqa " #offset " * 4096 (%6, %2, 1), %4\n\t" \
"vpcmpeqb %4, %7, %4\n\t" \
"vmovntdqa " #offset " * 4096 + 0x20 (%6, %2, 1), %3\n\t" \
"vpcmpeqb %3, %7, %3\n\t" \
"vpsubb %4, %0, %0\n\t" \
"vpsubb %3, %1, %1\n\t" \
We put 8 of these inside the main loop, with the offset set to 0 through 7.
This improves the score on HighLoad by some 15%, but if your kernel is even more memory bound, let’s say you just vpaddb the bytes to find their sum modulo 255, you can get up to 30% gain with this. Pretty cool for such a simple change!
Anyway, one other small thing: we add a prefetch for 4 cache lines ahead:
#define BLOCK(offset) \
"vmovntdqa " #offset " * 4096 (%6, %2, 1), %4\n\t" \
"vpcmpeqb %4, %7, %4\n\t" \
"vmovntdqa " #offset " * 4096 + 0x20 (%6, %2, 1), %3\n\t" \
"vpcmpeqb %3, %7, %3\n\t" \
"vpsubb %4, %0, %0\n\t" \
"vpsubb %3, %1, %1\n\t" \
"prefetcht0 " #offset " * 4096 + 4 * 64 (%6, %2, 1)\n\t"
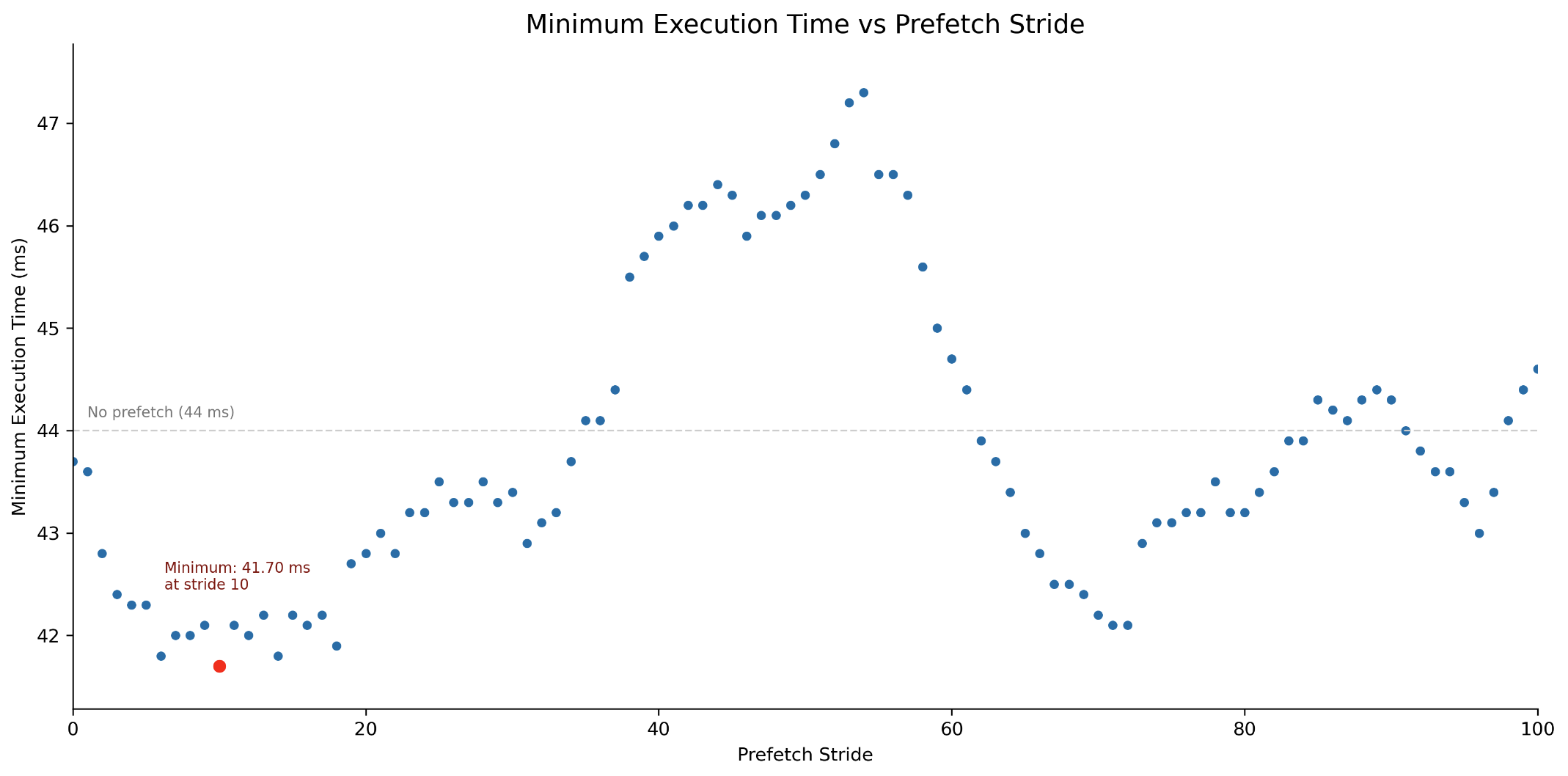
Why 4 lines ahead? I don’t have a good explanation for that, it’s simply what performs best. Below is a plot of runtime of the solution with prefetch strides from 0 to 100 on a different system (hence why the optimum is elsewhere here). As you can see the curve is quite complex.
The Source
#include <iostream>
#include <cstdint>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <immintrin.h>
#include <cassert>
#define BLOCK_COUNT 8
#define PAGE_SIZE 4096
#define TARGET_BYTE 127
#define BLOCKS_8 \
BLOCK(0) BLOCK(1) BLOCK(2) BLOCK(3) \
BLOCK(4) BLOCK(5) BLOCK(6) BLOCK(7)
#define BLOCK(offset) \
"vmovntdqa " #offset "*4096(%6,%2,1),%4\n\t" \
"vpcmpeqb %4,%7,%4\n\t" \
"vmovntdqa " #offset "*4096+0x20(%6,%2,1),%3\n\t" \
"vpcmpeqb %3,%7,%3\n\t" \
"vpsubb %4,%0,%0\n\t" \
"vpsubb %3,%1,%1\n\t" \
"prefetcht0 " #offset "*4096+4*64(%6,%2,1)\n\t"
static inline
__m256i hsum_epu8_epu64(__m256i v) {
return _mm256_sad_epu8(v, _mm256_setzero_si256());
}
int main() {
struct stat sb;
assert(fstat(STDIN_FILENO, &sb) != -1);
size_t length = sb.st_size;
char* start = static_cast<char*>(mmap(nullptr, length, PROT_READ, MAP_PRIVATE | MAP_POPULATE, STDIN_FILENO, 0));
assert(start != MAP_FAILED);
uint64_t count = 0;
__m256i sum64 = _mm256_setzero_si256();
size_t offset = 0;
__m256i compare_value = _mm256_set1_epi8(TARGET_BYTE);
__m256i acc1 = _mm256_set1_epi8(0);
__m256i acc2 = _mm256_set1_epi8(0);
__m256i temp1, temp2;
while (offset + BLOCK_COUNT*PAGE_SIZE <= length) {
int batch = PAGE_SIZE / 64;
asm volatile(
".align 16\n\t"
"0:\n\t"
BLOCKS_8
"add $0x40, %2\n\t"
"dec %5\n\t"
"jg 0b"
: "+x" (acc1), "+x" (acc2), "+r" (offset), "+x" (temp1), "+x" (temp2), "+r" (batch)
: "r" (start), "x" (compare_value)
: "cc", "memory"
);
offset += (BLOCK_COUNT - 1)*PAGE_SIZE;
sum64 = _mm256_add_epi64(sum64, hsum_epu8_epu64(acc1));
sum64 = _mm256_add_epi64(sum64, hsum_epu8_epu64(acc2));
acc1 = _mm256_set1_epi8(0);
acc2 = _mm256_set1_epi8(0);
}
sum64 = _mm256_add_epi64(sum64, hsum_epu8_epu64(acc1));
sum64 = _mm256_add_epi64(sum64, hsum_epu8_epu64(acc2));
count += _mm256_extract_epi64(sum64, 0);
count += _mm256_extract_epi64(sum64, 1);
count += _mm256_extract_epi64(sum64, 2);
count += _mm256_extract_epi64(sum64, 3);
for (; offset < length; ++offset) {
if (start[offset] == TARGET_BYTE) {
++count;
}
}
std::cout << count << std::endl;
return 0;
}
Conclusion
The page-interleaved read pattern seems surprisingly under-discussed and I don’t remember ever seeing it used in code in the wild. Curious! If you’re aware of it being used anywhere, let me know, I’d love to see it! And if I’m missing any other memory-based optimization, let me know too. :)