This sneaky 1-line change sped up subprocess#communicate 1000x+
Note: The performance issue discussed here has been fixed in Ruby 3.2!
One of my favorite little fixes I’ve done at Stripe unrelated to my day-to-day work was fixing an accidental O(n²) behavior of Subprocess#communicate that made communicating 1GB worth of data ~1000 times slower than it needed to be. This ended up reducing runtime of several batch jobs from days to minutes/hours, among other things.
The fix itself was this fun one-liner:

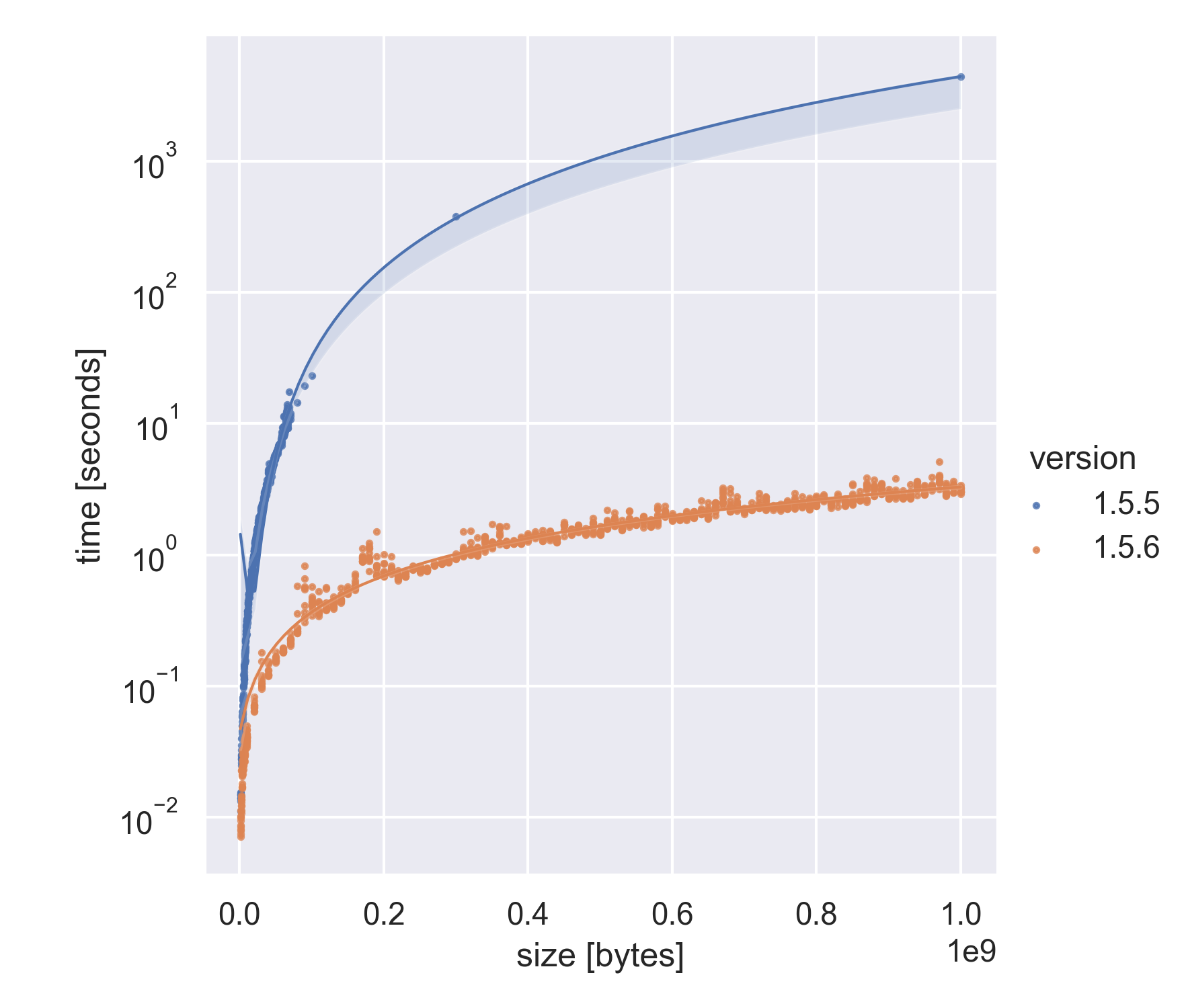
Which produced this speed-up when piping various amounts of data (note the y-axis is logarithmic):
Finding the Problem
It started with me noticing several batch jobs that generated small files from small inputs but ran for days, with implied bandwidth of literal bytes per second.
Identifying the offending line was just a matter of profiling the batch job code, which pointed out this line in Subprocess#communicate as being the culprit:
# Simplified Subprocess#communicate
def communicate(input=nil, timeout_s=nil)
# While we have data to communicate...
while !input.empty?
# write it to stdin...
written = @stdin.write_nonblock(input)
# and strip the amount written.
> input[0...written] = '' # Slow!!!
end
end
Which led me to this reproducer, which runs very slowly. (~1 hour for 1e9 bytes!)
# Strip `s` in 65535 byte chunks until it's empty
s = 'a' * 1e8 # 100MB
while s && s.length > 0
s[0...65535] = ''
end
Running ltrace summary on it shows a large number of memcpys, but is that too many or expected?
root@X:~# ltrace -c ruby slow.rb
% time seconds usecs/call calls function
------ ----------- ----------- --------- --------------------
75.94 58.910576 1435 41029 memcpy
8.18 6.346906 67 94195 malloc_usable_size
4.37 3.393178 70 48166 malloc
3.38 2.624438 66 39496 memcmp
1.49 1.153439 67 17214 calloc
Summing the last argument of all these
memcpys with awk shows
it’s moving 7.6e10 bytes (76GB) around, a whole lot more than the 1e8 bytes we
create in the script. On the other hand 7.6e10 (1e8/65535 * 1e8/2) is exactly
what I would expect to see if ruby was creating a new string every time we
shorten s.
How about the faster version then?
# Strip `s` in 65535 byte chunks until it's empty
s = 'a' * 1e8 # 100MB
while s && s.length > 0
s = s[65535..]
end
We do indeed see far fewer memcpys and they total to the expected 1e8 bytes.
root@X:~# ltrace -c ruby fast.rb
% time seconds usecs/call calls function
------ ----------- ----------- --------- --------------------
30.08 6.010816 65 91179 malloc_usable_size
15.46 3.089680 66 46230 malloc
13.48 2.693967 68 39506 memcpy
13.27 2.652020 67 39501 memcmp
5.69 1.137131 66 17214 calloc
Why is it Faster?
I believe input = input[x..input.length] triggers Shared String Optimization
that makes Ruby keep the original string buffer and only update/create new RString
pointing into it.
Here’s a detailed ltrace of the slow version:
> rb_str_aset_m(2, 0x7f8f7eeff060, 0x7f8f7b6d49f0, 0x5583934d8dd0 <unfinished ...>
str_strlen(0x7f8f7b6d49f0, 0, 0x7f8f7b6d49f0, 0x5583934d8dd0)
rb_range_beg_len(0x7f8f7b6d5210, 0x7ffc9f3a6ec8, 0x7ffc9f3a6ed0, 0xe4241 <unfinished ...>
rb_obj_is_kind_of(0x7f8f7b6d5210, 0x7f8f7ebd26c0, 0x7ffc9f3a6ed0, 0xe4241)
rb_str_update(0x7f8f7b6d49f0, 0, 0xffff, 0x7f8f7b6d4900 <unfinished ...>
rb_string_value(0x7ffc9f3a6e58, 0, 0xffff, 0x7f8f7b6d4900)
rb_enc_check(0x7f8f7b6d49f0, 0x7f8f7b6d4900, 5, 0x7f8f7b6d4900 <unfinished ...>
rb_enc_get_index(0x7f8f7b6d49f0, 0x7f8f7b6d4900, 5, 0x7f8f7b6d4900)
rb_enc_get_index(0x7f8f7b6d4900, 0x7f8f7b6d4900, 5, 0x7f8f7b6d4900)
str_strlen(0x7f8f7b6d49f0, 0x558394ea4ec0, 0, 1)
str_modify_keep_cr(0x7f8f7b6d49f0, 0x558394ea4ec0, 0, 1 <unfinished ...>
rb_enc_get(0x7f8f7b6d49f0, 0x558394ea4ec0, 5, 1 <unfinished ...>
rb_enc_get_index(0x7f8f7b6d49f0, 0x558394ea4ec0, 5, 1)
str_make_independent_expand(0x7f8f7b6d49f0, 0xe4241, 0, 1 <unfinished ...>
ruby_xmalloc2(0xe4242, 1, 0xe4242, 1 <unfinished ...>
objspace_xmalloc0(0x558394e9d800, 0xe4242, 0, 1 <unfinished ...>
malloc(934466)
malloc_usable_size(0x7f8f7b4c6010, 0xe4242, 0xe5002, 0x7f8f7b4c6010)
> memcpy(0x7f8f7b4c6010, "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"..., 934465)
You can clearly see the memcpy that ultimately comes from
rb_str_aset_m which is what String#[]= is defined
as, which in turn comes from this disassembly:
irb(main):001" code =<<END
irb(main):002" s = "foo"
irb(main):003" s[0...2] = ''
irb(main):004> END
=> "s = \"foo\"\ns[0...2] = ''\n"
irb(main):005> puts RubyVM::InstructionSequence::compile(code).disasm
== disasm: #<ISeq:<compiled>@<compiled>:1 (1,0)-(2,13)>
local table (size: 1, argc: 0 [opts: 0, rest: -1, post: 0, block: -1, kw: -1@-1, kwrest: -1])
[ 1] s@0
0000 putstring "foo"
0002 setlocal_WC_0 s@0 # s = "foo"
0004 putnil
0005 getlocal_WC_0 s@0
0007 putobject 0...2
0009 putstring ""
0011 setn 3
0013 opt_aset <calldata!mid:[]=, argc:2, ARGS_SIMPLE>[CcCr]
0015 pop # ^ call String#[]= on s with two args: (0..2, "")
0016 leave
The fast version on the other hand uses String#[] aka rb_str_aref_m:
irb(main):006" code =<<END
irb(main):007" s = "foo"
irb(main):008" s = s[2..]
irb(main):009> END
=> "s = \"foo\"\ns = s[2..]\n"
irb(main):010> puts RubyVM::InstructionSequence::compile(code).disasm
== disasm: #<ISeq:<compiled>@<compiled>:1 (1,0)-(2,10)>
local table (size: 1, argc: 0 [opts: 0, rest: -1, post: 0, block: -1, kw: -1@-1, kwrest: -1])
[ 1] s@0
0000 putstring "foo"
0002 setlocal_WC_0 s@0
0004 getlocal_WC_0 s@0
0006 putobject 2..
0008 opt_aref <calldata!mid:[], argc:1, ARGS_SIMPLE>[CcCr]
0010 dup # ^ call String#[] on s with one arg: 0..2
0011 setlocal_WC_0 s@0
0013 leave
And the associated ltrace:
> rb_str_aref_m(1, 0x7f78c0cff060, 0x7f78bd4cc948, 0x555ed63d7320 <unfinished ...>
str_strlen(0x7f78bd4cc948, 0, 0x7f78bd4cc948, 0x555ed63d7320)
rb_range_beg_len(0x7f78bd4cc8f8, 0x7ffff83c3248, 0x7ffff83c3250, 0xe4241 <unfinished ...>
rb_obj_is_kind_of(0x7f78bd4cc8f8, 0x7f78c09c66a8, 0x7ffff83c3250, 0xe4241)
str_substr(0x7f78bd4cc948, 0xffff, 0xd4242, 1 <unfinished ...>
rb_str_subpos(0x7f78bd4cc948, 0xffff, 0x7ffff83c31d0, 1 <unfinished ...>
get_encoding(0x7f78bd4cc948, 0xffff, 0, 1 <unfinished ...>
get_actual_encoding(1, 0x7f78bd4cc948, 1, 1 <unfinished ...>
rb_enc_from_index(1, 0x7f78bd4cc948, 1, 1)
rb_enc_get(0x7f78bd4cc948, 0x7f78bd4cc948, 0xffff, 1 <unfinished ...>
rb_enc_get_index(0x7f78bd4cc948, 0x7f78bd4cc948, 0xffff, 1)
rb_str_dup_frozen(0x7f78bd4cc948, 0x7f78bd4cc948, 0x7f78bd4cc948, 1 <unfinished ...>
rb_obj_class(0x7f78bd4cc948, 0x7f78bd4cc948, 5, 1)
str_new_frozen_buffer(0x7f78c09b2428, 0x7f78bd4cc948, 1, 1 <unfinished ...>
rb_wb_protected_newobj_of(0x7f78c09b2428, 5, 40, 0xffff)
> str_replace_shared_without_enc.isra.0(0x7f78bd4cc8d0, 0x7f78bd4cc970, 0x7f78bd4cc8d0, 0x555ed6b460e0 <unfinished ...>
No memcpy in sight! I believe str_replace_shared_without_enc is where the optimization happens, but frankly I find Ruby’s string.c quite confusing and not particularly well documented, so who knows!
Final Thoughts
While the change above works and I find the one-liner nature of it very fun, it’s probably not the best way of fixing this, since it relies on an optimization that could stop working. One should probably implement the pointer moving on their own.
If you understand string.c better I’d be very curious to know why the optimization triggers in one case but not the other. Is it a bug or a feature? Let me know!
Backlinks
Discussions on /r/ruby and /r/programming subreddits.